2. Container Orchestrierung (Swarm vs. Kubernetes)
In unserem letzten Bericht haben wir uns mit der Containerisierung von Anwendungen innerhalb eines Hosts beschäftigt. Für die Orchestrierung von Containern in einer verteilten Umgebung sind weitere Technolgien erforderlich. In diesem Bericht werden wir uns mit Docker Swarm und Kubernetes beschäftigen, die umfassende Funktionen zur Skalierung, Bereitstellung und Verwaltung von Anwendungen in containerisierten Umgebungen bieten. Zunächst werden beide Technologien einzeln vorgestellt und anschließend miteinander verglichen. Darüberhinaus wurde ein Beispiel für die Verwendung von Docker Swarm und Kubernetes in einem Projekt erstellt. Ein MongoDB-Cluster zusammen mit einer Flask-Anwendung wird mit beiden Technologien auf mehreren Hosts bereitgestellt.
2.1. Docker Swarm
Docker Swarm gibt es in zwei Versionen: Swarm Mode und Swarm Classic. Swarm Classic ist eine eigenständige Version von Docker Swarm, die nicht mehr aktiv weiterentwickelt wird, daher wird nur die zweite Version der Swarm Mode betrachtet. Diese ist direkt in die Docker Engine integrier und somit bereits auf allen Geräten verfügbar, auf denen Docker installiert ist. [DockerSwarm]
2.1.1. Konzepte
Docker Swarm basiert auf folgenden Konzepten:
- Swarm:
Ein Swarm ist ein Cluster von Docker-Hosts, die als eine einzige virtuelle Docker-Engine fungieren. Docker Swarm ermöglicht es, Container über mehrere Hosts hinweg zu verteilen und zu verwalten, wodurch eine höhere Skalierbarkeit und Verfügbarkeit von Anwendungen erreicht wird.
- Node:
Ein Node ist ein physischer oder virtueller Rechner, der dem Docker Swarm-Cluster beigetreten ist. Nodes können Manager- oder Worker-Nodes sein, wobei Manager-Nodes für die Verwaltung des Clusters und die Verteilung von Aufgaben verantwortlich sind, während Worker-Nodes die eigentlichen Container ausführen. EIn Node kann auch gleichzeitig als Manager- und Worker-Node fungieren.
- Service:
Ein Service definiert die gewünschten Zustände für eine Gruppe von replizierten Containern. Ein Service kann beispielsweise eine Webanwendung oder eine Datenbank darstellen und kann über mehrere Nodes hinweg repliziert werden.
- Task:
Ein Task ist eine Instanz eines Containers, der als Teil eines Services auf einem Node ausgeführt wird. Docker Swarm plant und verteilt automatisch Tasks auf verfügbaren Nodes, um die Spezifikationen des Services zu erfüllen. ManagerNodes verteilen die Tasks auf Worker-Nodes und überwachen deren Zustand.
- Load Balancing:
Docker Swarm bietet integriertes Load Balancing für Services, die über Ports veröffentlicht werden. (ingress load balancing)
2.1.2. Funktionalitäten
Mithilfe der oben genannten Konzepte kann Docker Swarm folgende Funktionalitäten bereitstellen:
Automatische Lastverteilung: Docker Swarm verteilt automatisch Tasks auf verfügbaren Nodes, um die Last gleichmäßig zu verteilen, was die Skalierbarkeit und Verfügbarkeit der Anwendungen verbessert.
Skalierbarkeit: Die Anzahl der Container-Instanzen eines Services kann einfach erhöht oder verringert werden.
Service Discovery: Docker Swarm bietet integrierte Service Discovery, die es ermöglicht, Services über einen DNS-Namen zu erreichen, der automatisch auf die IP-Adressen der Container-Instanzen gemappt wird.
Rolling Updates: Services werden mit minimaler Ausfallzeit aktualisiert, indem neue Container-Instanzen schrittweise bereitgestellt und alte Instanzen entfernt werden.
Sicherheit: Docker Swarm bietet integrierte Sicherheitsfunktionen wie TLS-Verschlüsselung und Rollenbasierte Zugriffskontrolle.
2.1.3. Verwendung
Nachfolgend sind einige grundlegende Befehle der Docker CLI aufgeführt, die für die Verwendung von Docker Swarm nützlich sind. Wenn nicht anders angegeben, werden die Befehle auf dem Manager-Node ausgeführt.
- Erstellung und Verwaltung eines Swarm-Clusters:
docker swarm init: Erstellt ein Swarm-Cluster auf einem Host, der als Manager-Node fungiertdocker swarm join --token <TOKEN>: Fügt einen Worker-Node zu einem Swarm-Cluster hinzu, das notwendige Token wird vom Manager-Node bereitgestellt (Ausführung auf dem Worker-Node)docker swarm leave: Entfernt einen Node aus dem Swarm-Clusterdocker node ls: Listet alle Nodes im Swarm-Cluster aufdocker node inspect <NODE-ID>: Zeigt detaillierte Informationen über einen Node andocker node promote <NODE-ID>: Befördert einen Worker-Node zum Manager-Node
- Erstellung und Verwaltung eines Services:
docker service create: Erstellt einen neuen Service mit den gewünschten Spezifikationen, wie z.B. Anzahl der Replikationen, Ports, Umgebungsvariablen, etc.docker service ls: Listet alle Services im Swarm-Cluster aufdocker service ps <SERVICE-ID>: Zeigt die Tasks eines Services andocker service scale <SERVICE-ID>=<REPLICAS>: Skaliert die Anzahl der Replikationen eines Servicesdocker service update: Aktualisiert die Spezifikationen eines Services, z.B. Anzahl der Replikationen, Umgebungsvariablen, etc.docker service rm <SERVICE-ID>: Entfernt einen Service aus dem Swarm-Clusterdocker service logs <SERVICE-ID>: Zeigt die Logs eines Services andocker service inspect <SERVICE-ID>: Zeigt detaillierte Informationen über einen Service an
- Veröffentlichen eines kompletten Anwendungsstacks:
- Erstellung einer Registry für die Speicherung von Images
docker service create --name registry --publish published=5000,target=5000 registry:2
docker stack deploy --compose-file compose.yml <STACK-NAME>: Veröffentlicht einen Anwendungsstack, der in einem Docker Compose-Datei definiert istdocker stack services <STACK-NAME>: Listet alle Services eines Anwendungsstacks aufdocker stack rm <STACK-NAME>: Entfernt einen Anwendungsstack aus dem Swarm-Cluster
2.2. Kubernetes
Was ist Kubernetes?
Kubernetes ist eine portable, erweiterbare Open-Source-Plattform zur Verwaltung von containerisierten Arbeitslasten und Services, die sowohl die deklarative Konfiguration als auch die Automatisierung erleichtert. [Kubernetes_overview]
Architektur
Die Kubernetes-Architektur besteht aus einer klaren Hierarchie:
Container: Ein Container enthält Anwendungen und Software-Umgebungen
Pod: Diese Einheit in der Kubernetes-Architektur versammelt Container, die für eine Anwendung zusammenarbeiten müssen
Node: Einer oder mehrere Pods laufen auf einem Node, der sowohl eine virtuelle als auch eine physikalische Maschine sein kann
Cluster: Mehrere Nodes werden bei Kubernetes zu einem Cluster zusammengefasst
Zudem basierend auf Master/Slave-Prinzip: Als Slave werden die beschriebenen Nodes eingesetzt. Sie stehen unter der Verwaltung und Kontrolle des Kubernetes-Masters.
Zu den Aufgaben eines Masters gehört es zum Beispiel, Pods auf Nodes zu verteilen. Durch die ständige Überwachung kann der Master auch eingreifen, sobald ein Node ausfällt, und diesen direkt doppeln, um den Ausfall zu kompensieren. Der Ist-Zustand wird immer mit einem Soll-Zustand verglichen und bei Bedarf angepasst. Solche Vorgänge geschehen automatisch. Der Master ist aber auch der Zugriffspunkt für Administratoren. Diese können darüber die Container orchestrieren. [Ionos_digitalguide]
Kubernetes in der Praxis
Der Slave ist ein physischer oder virtueller Server, auf dem ein oder mehrere Container aktiv sind. Auf dem Node befindet sich eine Laufzeitumgebung für die Container. Außerdem ist das Kubelet aktiv.
Kubelet: Bestandteil, der die Kommunikation zum Master ermöglicht. Die Komponente startet und stoppt zudem Container.
cAdvisor: Dienst für das Kubelet, der die Ressourcenauslastung aufzeichnet.
Kube-proxy: Führt System Load-Balancing durch und ermöglicht Netzwerkverbindungen über TCP oder andere Protokolle.
Der Master ist ebenfalls ein Server. Um die Kontrolle und Überwachung der Nodes zu gewährleisten, läuft auf dem Master der Controller Manager. Diese Komponente wiederum hat mehrere Prozesse in sich vereint:
Node Controller: Überwacht Nodes. Reagiert wenn ein Node ausfällt
Replication Controller: Stellt sicher, dass immer gewünschte Zahl von Pods läuft
Endpoints Controller: Steuert das Endpoint-Objekt, welches für die Verbindung von Services und Pods zuständig ist
Service Account & Token Controller: Verwalten Namespace und erstellen API-Zugriffstoken
Vor- und Nachteile
Vorteile |
Nachteile |
|---|---|
Skalierbarkeit |
Erlernbarkeit |
Ausfallsicherheit |
Komplexität |
Große Community |
2.3. Beispiel-Projekte
Anhand des Beispiels des Berichts der ersten Woche wollten wir einerseits die Verteilung von Containern auf mehrere Hosts, sowie das MongoDB ReplicaSet Feature mithilfe eines kleinen Beispiels ausprobieren. Ein ReplicaSet erreicht High Availability und Skalierbarkeit, indem es mehrere Instanzen einer MongoDB-Datenbank auf verschiedenen Hosts repliziert. Das im Folgenden beschriebene Setup haben wir einerseits mit Docker Swarm und andererseits mit Kubernetes aufgebaut.
2.3.1. Docker Swarm
Für die Verwendung von Docker Swarm haben wir der Einfachheit halber drei virtuelle Maschinen aufgesetzt, auf denen ein frisches Ubuntu 22.04 mit Docker installiert wurde. Eine der Maschinen wurde als Manager-Node und die anderen beiden als Worker-Nodes konfiguriert. Mit der folgenden compose.yml-Datei haben wir eine einfache Flask-Anwendung und ein MongoDB-ReplicaSet, bestehend aus drei Instanzen definiert:
version: "3"
services:
# Web Backend
flask-backend:
image: flask_backend:latest
stop_signal: SIGINT
environment:
- FLASK_SERVER_PORT=9090
- MONGODB_URI=mongodb://mongo1:7011,mongo2:7012,mongo3:7013
deploy:
replicas: 1
placement:
constraints: [node.role == manager] # should run on the manager to be accessible via browser
networks:
- mongo
ports:
- 9090:9090
volumes:
- ./flask:/app
depends_on:
- mongo1
# DB tasks
mongo1:
image: mongo:6
command: mongod --replSet swarm-test-mongo --port 7011
ports:
- 7011:7011
volumes:
- database:/data/db
- /etc/localtime:/etc/localtime:ro
deploy:
replicas: 1
placement:
constraints: [node.role == manager] # primary should be on the manager node
networks:
- mongo
mongo2:
image: mongo:6
command: mongod --replSet swarm-test-mongo --port 7012
ports:
- 7012:7012
volumes:
- database:/data/db
- /etc/localtime:/etc/localtime:ro
deploy:
replicas: 1
networks:
- mongo
mongo3:
image: mongo:6
command: mongod --replSet swarm-test-mongo --port 7013
ports:
- 7013:7013
volumes:
- database:/data/db
- /etc/localtime:/etc/localtime:ro
deploy:
replicas: 1
networks:
- mongo
# Basically Portainer for Docker Swarms
visualizer:
image: dockersamples/visualizer:latest
ports:
- 8080:8080
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager] # should run on the manager to be accessible via browser
networks:
- mongo
volumes:
database:
networks:
mongo:
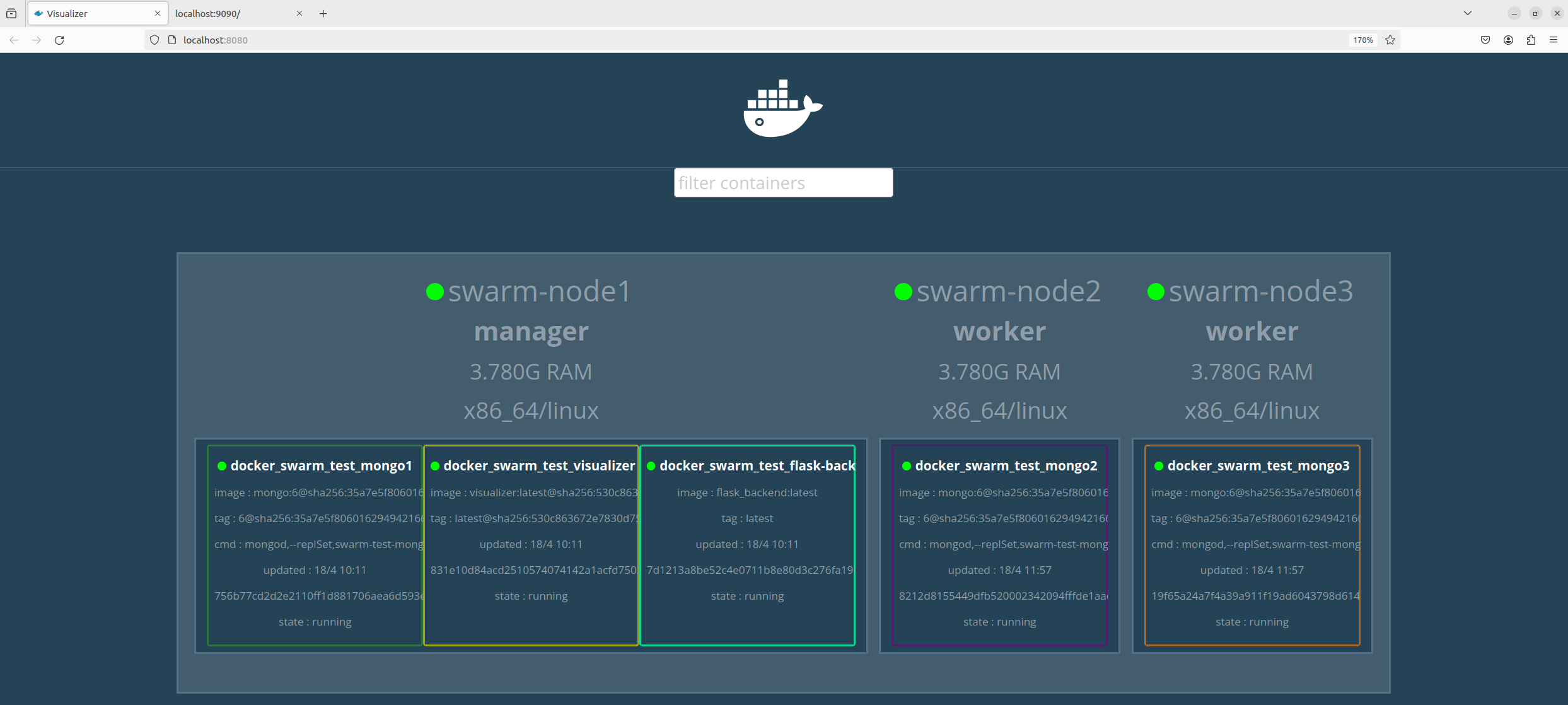
Das Flask-Backend frägt letztlich die Datenbank über jede der Instanzen an und gibt die Daten auf der Port 9090 aus. Die MongoDB-Instanzen sind so konfiguriert, dass sie ein ReplicaSet bilden. Der Visualizer dient dazu, die Verteilung der Container auf den Hosts zu visualisieren. Mit dem folgenden Skript wird der Swarm initialisert und der Stack auf ihm bereitgestellt:
#!/bin/bash
####################################################################################################
# This script creates the docker swarm example project with a Replica Set of three MongoDB instances
# Run this from the <...>/04/Woche_2/swarm_test directory
####################################################################################################
# Create directory for the shared db volume
mdkir database
docker swarm init
echo "Copy the 'docker swarm join <...>' command printed above and run it on all worker node machines."
# Wait for the user to be ready
read -p "Enter 'continue' to continue the setup: " input
while [[ $input != "continue" ]]
do
read -p "This was not correct, enter 'continue', to continue the setup: " input
done
# Build the image for the flask backend
docker build -t flask_backend:latest ./flask
# Start the swarm
docker stack deploy -c compose.yml docker_swarm_test
# Get the full name of the Mongo Primary to be able to access it
mongo=$(docker ps --format '{{.Names}}' | grep docker_swarm_test_mongo1)
# Initialize Replica Set
docker exec -it $mongo mongosh --port 7011 --eval "rs.initiate({
_id: \"replicaTest\",
members: [
{_id: 0, host: \"mongo1:7011\"},
{_id: 1, host: \"mongo2:7012\"},
{_id: 2, host: \"mongo3:7013\"}
]
})"
# Open status site and swarm viz
firefox localhost:9090 localhost:8080 &
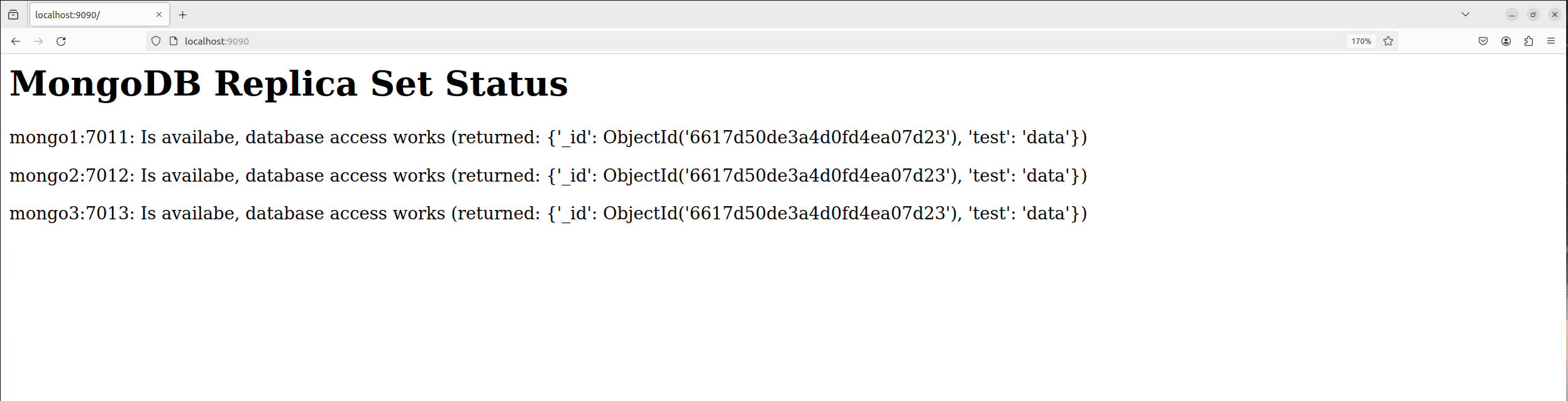
Der Befehl docker swarm init initialisiert den Swarm, dem die Worker-Nodes mit dem ausgegeben Befehl beitreten können. Da wir ein custom Image für das Flask-Backend verwenden, wird dieses zuvor mit docker build -t flask_backend:latest ./flask gebaut. Mit docker stack deploy -c compose.yml docker_swarm_test wird der Stack auf dem Swarm bereitgestellt. Danach muss das ReplicaSet initialisiert werden, indem man auf die Primary Instanz der MongoDB zugreift und das ReplicaSet mit initiiert. Letztlich wird die Flask-App auf dem Port 9090 und der Swarm-Visualizer auf dem Port 8080 geöffnet.
Swarm Visualizer auf localhost:8080
Flask Backend Output auf localhost:9090
2.3.2. Kubernetes
Kubernetes Installation
Installationsanleitung für Ubuntu
sudo apt update
sudo apt upgrade
# Disable Swap
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# Add Kernel Parameters
sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
# Reload Kernel Parameters
sudo sysctl --system
# Install Docker
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# Install Docker Packages
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Install containerd
sudo apt update
sudo apt install -y containerd.io
# Configure containerd
containerd config default | sudo tee /etc/containerd/config.toml >/dev/null 2>&1
sudo sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/g' /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl enable containerd
# Install Kubernetes
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# This overwrites any existing configuration in /etc/apt/sources.list.d/kubernetes.list
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
Ab hier beginnt die Installation mit „sudo kubeadm init“ und auf den Pods mit „kubeadm join …“
[KubernetesInstallationUbuntu] [KubernetesInstallation] [DockerInstallation]
Kubernetes und seine Probleme
Kubernetes ist eine Katastrophe zum aufsetzen. Wir haben 3 Anläufe benötigt eine funktionierende Umgebung aufzusetzen.
Dabei hatten unter anderem folgende Probleme:
minikube: Die Spielerische Kubernetes Umgebung mit kubeadm hat zu Beginn sehr gut begonnen und das Cluster konnte erfolgreich aufgesetzt werden, jedoch gab es dann Probleme mit den Portfreigaben. minikube nutzte als Containerisierungsumgebung Docker, in welchem es dann einen minikube Container anlegte, der auch die einzelnen Pods beherbergte. Problem war nur jetzt, der minikube Container wollte nicht wirklich Ports nach außen öffnen, um auf das MongoDB Cluster zuzugreifen. In den Container reinspringen und dort alles über die bash zu machen ging, war aber keine schöne Lösung. Einzelne Pods anbinden über das Hostsystem ging auch, aber nicht das Kluster im gesammten.
Linux vServer: Beim Versuch ein Kubernetes Cluster mit Hilfe von 3 Linux vServer basierend auf Ubuntu 22 aufzusetzen, hatten wir mit kubeadm das Problem, dass dieses den Kernel Parameter net.bridge.bridge-nf-call-iptables=1 verlangte, aber egal mit welchem Command, das System hat diesen nicht angwendet. -> Installation nicht möglich
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
Linux vServer: Zusätzlich meckerte kubeadm auch stehts an, dass containerd nicht läuft. Lösung des Problems war ab das einfache Löschen der config.toml Datei. Trotzdem nervig und unschön :(
[ERROR CRI]: container runtime is not running: output: time="2024-04-14T17:33:59+02:00" level=fatal msg="validate service connection: validate CRI v1 runtime API for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
UTM: Auf der Apple MacOS (M2) Virtualisierungsumgebung UTM gab es während des kubeadm join Befehls auch Probleme, weil es nicht möglich war, innerhalb von UTM die Ports so zwischen den VMs freizugeben, dass eine Kommunikation zwischen diesen möglich war.
2.4. Vergleich Docker und Kubernetes
Der Hauptunterschied zwischen Docker und Kubernetes besteht in der Vorgehensweise der Containerisierung. Während Docker einen Container an sich gut organisieren kann, ermöglicht Kubernetes die Einbindung der einzelnen Container in ein komplexes System. Docker Swarm bietet ähnliche Konzepte wie Kubernetes, trotzdem existieren einige wesentlichen Unterschiede:
Docker Swarm |
Kubernetes |
|---|---|
Einfach zu lernen |
Komplexer, schwieriger zu lernen |
Dicht in das Docker Ecosystem miteingebunden |
Großes Open-Source Ecosystem |
Umständlich für komplexere Anwendungen |
Gut für komplexere Anwendungen |
Wenige Konfigurationsmöglichkeiten |
Große Konfigurationsmöglichkeiten |
Limitierte Funktionen |
Viele Funktionen zur Auswahl, einfache Erweiterbarkeit durch Open Source |
Insgesamt ist Docker Swarm gut geeignet für die simple und einfache Vernetzung von wenigen Containern. Dagegen wird Kubernetes zwingend nötig, sobald eine größere Anzahl von Containern miteinander kommunizieren möchten. Besonders bei größeren Einschränkungen im System und Konfigurationen ist Kubernetes unabdingbar. Ein typischer Anwedungsfall für die Nutzung von Kubernetes sind verteilte Systeme über mehrere Hostings hinweg.
2.5. Literaturangaben
Docker Docs: Swarm mode key concepts. https://docs.docker.com/engine/swarm/key-concepts/ (abgerufen am 12.04.2024)
Docker Docs: Swarm mode overview. https://docs.docker.com/engine/swarm/ (abgerufen am 12.04.2024)
Ionos Homepage https://www.ionos.de/digitalguide/server/knowhow/was-ist-kubernetes/ (abgerufen am 11.04.2024)
Kreyman Hompage https://www.kreyman.de/index.php/kubernetes/214-kubernetes-vor-und-nachteile-architekturbeschreibung (abgerufen am 11.04.2024)
Kubernetes Hompage https://kubernetes.io/de/docs/concepts/overview/what-is-kubernetes/ (abgerufen am 11.04.2024)
Lise Homepage https://www.lise.de/blog/artikel/kubernetes-vs-docker/ (abgerufen am 11.04.2024)
Atlassian: Kubernetes und Docker im Vergleich. https://www.atlassian.com/de/microservices/microservices-architecture/kubernetes-vs-docker (abgerufen am 16.04.2024)