5. Python Frameworks für Maschinelles Lernen und Neuronale Netze
In dieser Woche haben wir uns mit verschiedenen Python-Bibliotheken und Frameworks für maschinelles Lernen und neuronale Netze beschäftigt. Dazu gehören unter anderem PyTorch, Scikit-learn, Keras und TensorFlow. Jedes dieser Frameworks hat seine Stärken und Anwendungsbereiche, die wir im Folgenden genauer beleuchten wollen. Mit jedem dieser Frameworks haben wir eine Klassifikationsmodell basierend auf dem Datensatz CIFAR-10 umgesetzt. Darüberhinaus haben wir uns mit HuggingFace, LangChain, LlamaIndex beschäftigt.
5.1. CIFAR-10
Der CIFAR-10 Datensatz ist ein bekannter Datensatz für Bilderkennung und Klassifikation. Er besteht aus 60.000 farbigen Bildern im Format 32x32 Pixel, die in 10 Klassen unterteilt sind. Jede Klasse enthält 6.000 Bilder. Die Bilder sind den folgenden Klassen zugeordnet: Flugzeuge, Autos, Vögel, Katzen, Rehe, Hunde, Frösche, Pferde, Schiffe und Lastwagen. Der Datensatz ist in Trainings- und Testdaten aufgeteilt, wobei der Trainingsdatensatz 50.000 Bilder und der Testdatensatz 10.000 Bilder enthält. [CIFAR-10]
5.2. Pytorch
PyTorch ist eine auf Maschinelles Lernen ausgerichtete Open-Source-Programmbibliothek für die Programmiersprache Python, basierend auf der in Lua geschriebenen Bibliothek Torch, die bereits seit 2002 existiert. - Entwickelt vom Facebook-Forschungsteam für künstliche Intelligenz - PyTorch Foundation wurde im September 2022 gegründet und ist Teil der Linux Foundation
Installation Den Befehl für die Installation von PyTorch kann man sich auf der offiziellen Webseite von PyTorch generieren lassen.

Verwendete Bibliotheken
Projekt |
Beschreibung |
|---|---|
AllenNLP |
Design und Entwicklung von Natural-language-processing-Modellen |
advertorch |
Umgang mit abweichenden Trainingsdaten |
BoTorch |
Module für Künstliche neuronale Netze, GPU- und Autograd-Unterstützung |
ELF |
Lösen von Computerspielen |
fastai |
Bilderkennung/ Texterkennung/ Tabellenkalkulation/ Kollaboratives Filtern |
flair |
Natural language processing (Computerlinguistik) |
glow |
Compileroptimierung und Codegenerierung von neuronalen Netzwerkgraphen |
GPyTorch |
Gauß-Prozesse mit Berechnungen durch den Grafikprozessor |
Horovod |
Verteiltes Deep Learning mit Performance-Optimierungen durch Übertragungen zwischen den Knoten, die auf dem Message Passing Interface basieren. |
ignite |
Trainieren von Künstlich neuronalen Netzen |
ParlAI |
Austausch von großen Datensets zum Trainieren/Testen von Deep Learning-Anwendungen |
pennylane |
Quantencomputing im Bereich Maschinelles Lernen, Automatisches Differenzieren und Optimierung |
PySyft |
Datensicherheit/ Datenverarbeitung |
PyTorch geometric |
Erkennung geometrischer Muster |
PyTorch Lightning |
Automatisierung |
Pyro |
Statistik-, Prognosen- und Wahrscheinlichkeitsrechnung |
skorch |
Implementierung von Scikit-learn-Funktionen |
TensorLy |
Tensoranalysis/ Tensoralgebra |
Translate |
Maschinelle Übersetzung |
torchvision |
Bilderkennung |
torchtext |
Texterkennung |
torchaudio |
Sprach- und Audioerkennung |
5.2.1. CNN-Modell mit PyTorch
Ein Convolutional Neural Network (CNN) ist ein spezieller Typ von neuronalem Netzwerk, der besonders gut für die Verarbeitung von Bildern geeignet ist. Für CIFAR-10 wurde folgendes CNN-Modell in PyTorch implementiert:
num_epochs = 100
batch_size = 50
learning_rate = 0.001
momentum = 0.9
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
#Init_channels, channels, kernel_size, padding)
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.conv3 = nn.Conv2d(32, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2,2)
# Linear layer (64x4x4 -> 500)
self.fc1 = nn.Linear(64 * 4 * 4, 500)
# Linear Layer (500 -> 120)
self.fc2 = nn.Linear(500, 120)
# Linear Layer (120 -> 10)
self.fc3 = nn.Linear(120, 10)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
# Flatten the image
x = x.view(-1, 64*4*4)
x = self.dropout(x)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
5.3. Scikit-learn
Scikit-learn ist eine Open-Source-Bibliothek für maschinelles Lernen in Python, frei nutzbar unter der BSD Lizenz. Aufbauend auf den Python-Bibliotheken NumPy und SciPy bietet sie einfache und effiziente Werkzeuge für die Datenanalyse und -verarbeitung. Dadurch eignet sie sich für verschiedene Anwendungsbereichen wie Klassifikation, Regression, Clustering, Modellauswahl oder Daten-Vorverarbeitung. [Scikit-learn]
Die Bibliothek entstand 2007 als Google Summer of Code-Projekt von David Cournapeau und wurde seitdem von einer Vielzahl von Entwicklern weiterentwickelt. Heute ist Scikit-learn eine der wichtigsten Bibliotheken für maschinelles Lernen in Python und wird von einer großen Community unterstützt. Das Projekt ist größtenteils community-getrieben, wird aber auch von einigen Institutionen wie Microsoft, Nvidia oder Huggingface unterstützt. Aus dem Projekt hat sich außerdem eine Foundation (Scikit-learn Consortium at Inria Foundation) entwickelt, die die Weiterentwicklung und Pflege der Bibliothek sicherstellt. [Scikit-learn_About]
Installation
Die Installation von Scikit-learn erfolgt über pip, den Python-Paketmanager. Dazu wird der Befehl pip install scikit-learn in der Kommandozeile ausgeführt.
5.3.1. Hauptfunktionalitäten
Estimators: Scikit-learn biete eine Vielzahl an integrierten Algortihmen und Modelle für maschinelles Lernen. Diese werden als Estimators bezeichnet und können für Klassifikation, Regression, Clustering oder Dimensionalitätsreduktion verwendet werden. Jedes Modell kann mit der Methode fit() trainiert und mit predict() Vorhersagen getroffen werden. Für das Training wird eine Featurematrix X und die Zielwerte y in Form von numpy-arrays benötigt. Beim Vorhersagen wird für ein gegebenes Eingabe-Array X der Zielwert y durch das Modell bestimmt und zurückgegeben.
Transformationen: Neben den Estimators bietet Scikit-learn auch eine Reihe von Transformern, die die Daten vor der Verarbeitung transformieren. Dazu gehören beispielsweise die Skalierung der Daten, die Normalisierung oder die Reduktion der Dimensionalität. Die Transformationsmethoden können mit der Methode transform() aufgerufen werden.
Pipelines: Die Kombination von Estimators und Transformern erfolgt in Scikit-learn über Pipelines. Diese ermöglichen es, mehrere Schritte der Datenverarbeitung zu kombinieren und als ein Modell zu behandeln. Die Pipelines können mit der Methode fit() angepasst und mit predict() Vorhersagen getroffen werden.
Evaluation: Scikit-learn bietet eine Vielzahl von Methoden zur Bewertung von Modellen. Dazu gehören beispielsweise die Berechnung von Genauigkeit, Präzision, Recall oder F1-Score für Klassifikationsmodelle. Außerdem bietet die Bibliothek Funktionen zur Validierung von Modellen, wie Kreuzvalidierung oder Trainings-Test-Split, um das Datenset in Trainings- und Testdaten zu unterteilen.
Hyperparameter-Optimierung: Es ist oft notwendig, die Parameter der Modelle und Algorithmen zu optimieren. Scikit-learn bietet dazu verschiedene Methoden wie GridSearchCV oder RandomizedSearchCV, um die besten Hyperparameter für ein Modell zu finden. Diese verwenden den Ansatz der Kreuzvalidierung, um die Leistung des Modells zu bewerten und die beste Konfiguration der Parameter zu ermitteln. Diese kann mittels der Methode best_params_ abgerufen werden. [Scikit-learn_functionality]
5.3.2. Wozu wird Scikit-learn verwendet?
Scikit-learn wird in vielen Bereichen der Datenanalyse und des maschinellen Lernens eingesetzt. Es können verschiedenen Anwendungsfälle aus dem supervised und unsupervised learning umgesetzt werden. Dazu zählen vor allem die folgenden Bereiche:
Klassifikation: Vorhersage von Kategorien oder Labels für gegebene Daten
Regression: Vorhersage von kontinuierlichen Werten
Dimensionsreduktion: Reduzierung der Anzahl von Features in einem Datenset
Datenvorverarbeitung und -visualisierung: Bereinigung und Aufbereitung von Daten, um sie für die Modellierung vorzubereiten
Für den Aufbau neuronaler Netze und Deep Learning-Modelle ist Scikit-learn jedoch weniger geeignet. Ein rudimentärer Aufbau von neuronalen Netzen ist zwar möglich, jedoch nicht so leistungsfähig wie mit spezialisierten Bibliotheken (bspw. TensorFlow oder PyTorch). Für die Implementierung von Deep Learning-Modellen sind daher andere Bibliotheken besser geeignet. [Scikit-learn_usecases]
5.3.3. Trainieren eines eigenen Modells
Als Beispiel wurde der zu Beginn beschriebene CIFAR-10 Datensatz gewählt, um ein Klassifikationsmodell zu trainieren. Zur Implementierung wurde ein Jupyter Notebook verwendet, da es eine interaktive Umgebung bietet, um den Code schrittweise auszuführen und die Ergebnisse zu visualisieren. Es folgende Schritte durchgeführt werden:
1. Laden des Datensatzes:
Der CIFAR-10 Datensatz kann direkt von Scikit-learn geladen werden. Dazu wird die Methode fetch_openml aufgerufen, die den Datensatz in Form eines Dictionaries zurückgibt. Die Bilder sind im Schlüssel data und die Labels in target gespeichert.
cifar10 = fetch_openml('CIFAR_10', version=1)
2. Vorverarbeiten der Daten:
Zunächst werden die Daten in numpy arrays konvertiert, da der vorherige Schritt ein pandas Dataframe zurückgegeben hat und dieser etwas umständlicher zu handhaben ist. Danach werden die Daten in Trainings- und Testdaten aufgeteilt, um das Modell zu trainieren und zu evaluieren. Hierfür bietet Scikit-learn die Methode train_test_split. Im Anschluss werden die Daten für bessere Trainingsergebnisse normalisiert sowie standardisiert. Die Standardisierung kann einfach über die Klasse StandardScaler durchgeführt werden.
x = cifar10.data.to_numpy()
y = cifar10.target.astype(int).to_numpy()
# Aufteilen in Trainings- und Testdatensatz
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=1/6, random_state=42)
print('Trainingsdatensatz:', x_train.shape, y_train.shape)
print('Testdatensatz:', x_test.shape, y_test.shape)
# Normalisieren der Pixelwerte auf den Bereich [0, 1]
x_train = x_train / 255.0
x_test = x_test / 255.0
# Standardisieren der Daten (auf Mittelwert 0 und Standardabweichung 1)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
3. Trainieren des Modells:
Es wird ein MLPClassifier verwendet, da es in Scikit-learn nicht die Möglichkeit gibt, ein Convolutional Neural Network (CNN) zu erstellen. Ein CNN wäre für die Bilderkennung besser geeignet, da es die räumliche Struktur der Bilder berücksichtigt. Ein MLPClassifier ist ein einfaches neuronales Netzwerk, welches nur aus einem Input-Layer, beliebigen Hidden-Layer und einem Output-Layer besteht. Man kann beliebige Konfigurationsmöglichkeiten wählen, wie die Aktivierungsfunktion, die Anzahl der Neuronen pro Hidden-Layer sowie die Dauer des Trainings.
# Initialisieren des MLP Classifiers
mlp = MLPClassifier(hidden_layer_sizes=(1024, 256), activation='relu', solver='adam', batch_size=128, max_iter=50, verbose=True)
# Trainieren des Modells
mlp.fit(x_train, y_train)
4. Evaluieren des Modells:
Nach dem Training wird das Modell auf den Testdaten evaluiert, um die Genauigkeit und andere Metriken zu bestimmen. Dazu wird die Methode accuracy_score aufgerufen, die die Genauigkeit des Modells auf den Testdaten zurückgibt. Außerdem gibt es die Möglichkeit sich einen Klassifikationsbericht ausgeben zu lassen, der pro Klasse die Werte Precision, Recall und F1-Score ausgibt. Dies funktioniert durch Aufrufen der Methode classification_report. Neben diesen Metriken ist die Konfusionsmatix für Klassifizierungsmodelle von Bedeutung. Diese kann mit der Methode confusion_matrix erzeugt und visualisiert werden. Für das oben konfigurierte Modell sieht diese Matrix nach 50 Epochen Training folgendermaßen aus:
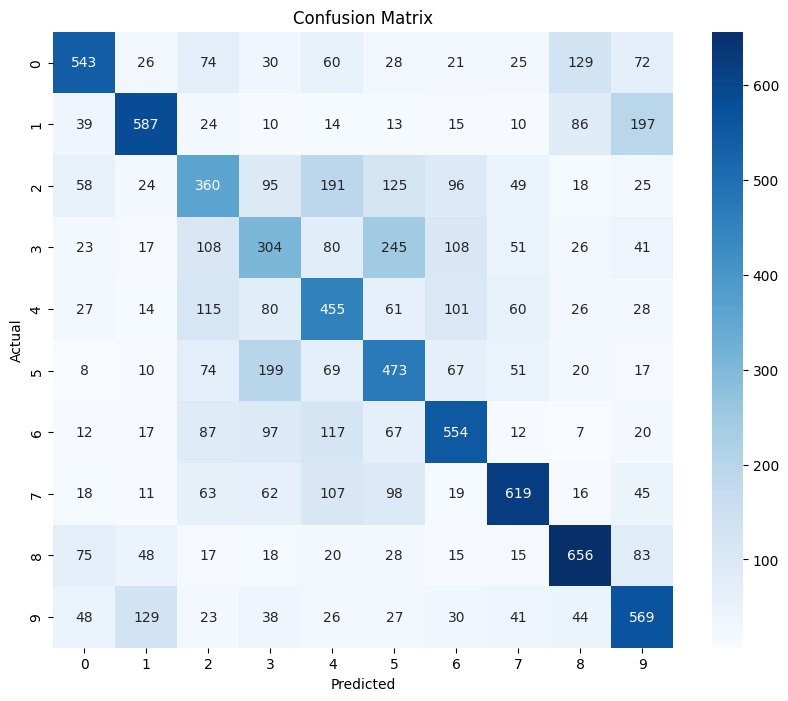
Daraus wird deutlich, dass das Modell manche Klassen gut erkennen kann, während es bei anderen Klassen Schwierigkeiten hat. Die Genauigkeit des Modells beträgt 0.51, was bedeutet, dass es 51% der Testdaten korrekt klassifiziert hat. Dies ist ein relativ niedriger Wert, der auf die Einfachheit des Modells und die Komplexität des Datensatzes zurückzuführen ist. Ein CNN-Modell würde hier wahrscheinlich bessere Ergebnisse liefern.
5.4. Keras
Keras ist eine benutzerfreundliche Open-Source-Bibliothek, die eine High-Level-API für die Entwicklung und das Training von Deep-Learning-Modellen bietet. Es ist in TensorFlow integriert und unterstützt verschiedene Backends, darunter TensorFlow, Theano und CNTK. Keras ist besonders bekannt für seine Einfachheit und Benutzerfreundlichkeit, was es ideal für Einsteiger und schnelle Prototypenentwicklung macht. In diesem Abschnitt beleuchten wir die Hauptmerkmale von Keras und zeigen ein praktisches Beispiel zur Modellierung eines neuronalen Netzes mit dem MNIST-Datensatz.
Installation Die Installation von Keras erfolgt über TensorFlow, das Keras bereits integriert hat. Dies liegt daran, dass TensorFlow seit Version 2.x Keras als offizielle High-Level-API integriert hat. Die Installation kann mit dem folgenden Befehl durchgeführt werden:
pip install tensorflow
TensorFlow ist notwendig, weil es das Haupt-Backend bereitstellt, das die eigentliche Berechnung und das Training der Modelle durchführt. Keras fungiert als eine Abstraktionsebene, die die Nutzung dieser komplexen Berechnungen vereinfacht.
Warum TensorFlow? TensorFlow ist eines der am weitesten verbreiteten Frameworks für maschinelles Lernen und bietet eine robuste und skalierbare Plattform für die Entwicklung von Deep-Learning-Modellen. Es ermöglicht die Nutzung von GPUs und TPUs, was die Trainingszeit erheblich verkürzen kann. Die Integration von Keras in TensorFlow vereinfacht die Nutzung und bietet gleichzeitig Zugriff auf die leistungsfähigen Funktionen von TensorFlow.
Alternativen zu TensorFlow als Backend
JAX: Ein von Google entwickeltes Framework für maschinelles Lernen, das automatische Differenzierung und optimierte numerische Berechnungen ermöglicht. JAX ist besonders für seine Fähigkeit bekannt, Numpy-Code zu beschleunigen und GPU- sowie TPU-Beschleunigung zu unterstützen. Es ist ein flexibles und leistungsfähiges Werkzeug für die Entwicklung moderner Deep-Learning-Modelle.
PyTorch: Ein von Facebook entwickeltes Deep-Learning-Framework, das besonders für seine dynamische Graph-Architektur und Benutzerfreundlichkeit bekannt ist. PyTorch wird häufig in der Forschung verwendet und bietet eine breite Palette an Funktionen für maschinelles Lernen. Es unterstützt GPU-Beschleunigung und hat eine große und aktive Community, was es zu einer beliebten Wahl für Entwickler macht.
Warum Alternativen verwenden? Die Wahl des Backends kann je nach spezifischen Anforderungen und Präferenzen variieren. Hier sind einige Gründe, warum man ein alternatives Backend in Betracht ziehen könnte:
Performance und Skalierbarkeit: Andere Backend wie JAX oder PyTorch, können in bestimmten Szenarien effizienter sein und eine bessere Skalierbarkeit bieten.
Spezifische Funktionen: Einige Frameworks bieten einzigartige Funktionen oder Optimierungen, die für bestimmte Anwendungen von Vorteil sein können.
Präferenz und Vertrautheit: Entwickler, die bereits Erfahrung mit einem bestimmten Framework haben, könnten dieses bevorzugen, um von ihrer vorhandenen Expertise zu profitieren.
Vor- und Nachteile von Keras
Vorteile
Einfachheit und Benutzerfreundlichkeit: Keras bietet eine einfache und konsistente API, die es Anfängern leicht macht, Modelle zu erstellen und zu trainieren. Die Syntax ist intuitiv und erfordert weniger Codezeilen im Vergleich zu anderen Frameworks.
Modularität: Keras-Modelle sind modular aufgebaut, was eine einfache Anpassung und Erweiterung ermöglicht. Verschiedene Komponenten wie Schichten, Optimierer und Verlustfunktionen können leicht kombiniert und ausgetauscht werden.
Integration mit TensorFlow: Die vollständige Integration mit TensorFlow bietet Zugang zu einer Vielzahl von Funktionen und ermöglicht die Nutzung der TensorFlow-Backend-Funktionen. Dies schließt die Nutzung von GPU- und TPU-Beschleunigung ein.
Große Community und Unterstützung: Keras hat eine große und aktive Community, die zahlreiche Tutorials, Beispiele und Dokumentationen bereitstellt. Dies erleichtert den Einstieg und die Lösung von Problemen.
Nachteile
Leistung: Obwohl Keras für viele Anwendungen ausreichend ist, kann es bei sehr großen Modellen oder speziellen Anforderungen zu Leistungseinbußen kommen. Die High-Level-Abstraktion von Keras kann zusätzliche Overheads erzeugen, die in sehr anspruchsvollen Szenarien problematisch sein können.
Abhängigkeit von TensorFlow: Keras ist eng mit TensorFlow verbunden, was die Verwendung anderer Backends weniger praktikabel macht. Dies kann zu Einschränkungen führen, wenn spezielle Funktionen oder Optimierungen eines anderen Frameworks benötigt werden.
Nicht optimal für sehr große Projekte: Für sehr große und komplexe Projekte, die spezielle Optimierungen und feinkörnige Kontrolle erfordern, kann Keras zu abstrakt und weniger effizient sein. In solchen Fällen kann ein direkterer Zugriff auf TensorFlow oder die Verwendung von PyTorch vorteilhafter sein.
Beispiel: Klassifikation mit Keras und MNIST
Das folgende Beispiel zeigt die Erstellung, das Training und die Evaluierung eines einfachen neuronalen Netzes zur Klassifikation des MNIST-Datensatzes. Der MNIST-Datensatz besteht aus handschriftlichen Ziffern und wird häufig zur Demonstration und Evaluierung von Bildklassifikationsmodellen verwendet.
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
# Laden des MNIST-Datensatzes
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalisieren der Eingabedaten
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# Umwandeln der Labels in One-Hot-Encoding
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# Erstellen des Modells
model = Sequential()
model.add(Flatten(input_shape=(28, 28))) # Eingabeschicht, die 28x28 Bilder flach macht
model.add(Dense(128, activation='relu')) # Versteckte Schicht mit 128 Neuronen und ReLU-Aktivierung
model.add(Dense(10, activation='softmax')) # Ausgabeschicht mit 10 Neuronen (für die 10 Klassen) und Softmax-Aktivierung
# Kompilieren des Modells
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trainieren des Modells
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.2)
# Evaluieren des Modells
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_accuracy}')
Ergebnisse
Nach dem Training des Modells mit 5 Epochen und einer Batch-Größe von 32, erreichte das Modell eine Testgenauigkeit von 0,972. Dies zeigt, dass das Modell in der Lage ist, handschriftliche Ziffern mit hoher Genauigkeit zu klassifizieren.
Zusammenfassung
Keras ist eine ausgezeichnete Wahl für Entwickler, die schnell und einfach leistungsfähige Deep-Learning-Modelle erstellen möchten. Die Integration mit TensorFlow bietet eine robuste Basis für fortgeschrittene Anwendungen und Forschungen im Bereich des maschinellen Lernens. Trotz einiger Einschränkungen in Bezug auf Leistung und Skalierbarkeit bleibt Keras aufgrund seiner Benutzerfreundlichkeit und Flexibilität ein bevorzugtes Tool in der Deep-Learning-Community.
5.5. Tensorflow
TensorFlow ist ein Open-Source-Framework für maschinelles Lernen, das von Google entwickelt wurde. Es wird häufig in der Forschung und in der Industrie für Deep Learning-Anwendungen wie Bild- und Texterkennung eingesetzt. TensorFlow ermöglicht es, Modelle auf verschiedenen Recheneinheiten wie CPUs, GPUs und TPUs (Tensor Processing Units) zu trainieren. Seit der Veröffentlichung von TensorFlow 2.0 im Oktober 2019 und dem damit verbundenen Umstieg auf die Keras API ist TensorFlow noch benutzerfreundlicher und leichter zu erlernen. Alleine lässt sich TensorFlow heute fast schon nicht mehr verwenden, da Keras gänzlich in die API integriert wurde und als High-Level-API für TensorFlow dient. Implementierungen ohne Keras sehen ein Downgrade auf die Version 1.x vor. Die Architektur von TensorFlow unterstützt viele Umgebungen, einschließlich Desktop, Mobile, Web und Cloud. Es bietet auch eine vereinfachte Schnittstelle namens Keras, die besonders für Einsteiger im Deep Learning geeignet ist. TensorFlow zeichnet sich durch seine Flexibilität und Skalierbarkeit aus und wird durch eine aktive Open-Source-Gemeinschaft ständig weiterentwickelt. [TensorFlow]
5.5.1. Tensorflow 1.x vs 2.x mit Keras
TensorFlow 1.x und TensorFlow 2.x unterscheiden sich grundlegend in ihrer Herangehensweise und Integration mit Keras. Für TensorFlow 1.x Eager Execution war nicht standardmäßig aktiviert, was bedeutet, dass der Code innerhalb einer Session ausgeführt werden musste, um Ergebnisse zu erhalten. Im Gegensatz dazu ist es in der v2 nun standardmäßig aktiviert, was eine sofortige Auswertung von Operationen ermöglicht und die Notwendigkeit von Sessions eliminiert.
Keras war in der Version 1.x noch eine separate Bibliothek, die als High-Level-API für TensorFlow diente. Seit TensorFlow 2.x ist Keras vollständig in TensorFlow integriert und wird als tf.keras bezeichnet. Dies vereinfacht die Modellerstellung und -training erheblich. Generell ist die API komplexer und weniger konsistent. Es gab viele redundante APIs und die Verwendung von tf.Session war erforderlich. In TensorFlow 2.x wurde die API bereinigt und vereinfacht, um die Benutzerfreundlichkeit zu verbessern. Zum Beispiel lassen sich Python-Funktionen mit tf.function in TensorFlow-Graphen umwandeln, was die Integration von TensorFlow in Python-Code erleichtert. Zudem basiert der Kontrollfluss in TensorFlow 1.x noch auf eigenen Konstrukten, weshalb die Sessions notwendig waren. Auch das wurde in der neuen Version umgangen und durch Python-native Kontrollfluss-Operationen ersetzt. [TensorFlow1v2]
5.5.2. Installation
Die Installation erfolgt auch hier über pip, den Python-Paketmanager. Dazu wird der Befehl pip install tensorflow in der Kommandozeile ausgeführt. Da jedoch für die testweise Verwendung von TensorFlow ohne Keras die Version 1.x installiert werden muss, wird der Befehl pip install tensorflow==1.15.1 verwendet. Diese wird außerdem nur auf Python 3.6 bis 3.8 unterstützt, weshalb hier in einem Docker Container gearbeitet wird:
# 3.7 is necessary for using tensorflow 1.x (the one without keras)
FROM python:3.7
WORKDIR /app
COPY . /app
RUN pip install --upgrade pip
RUN pip install jupyter
EXPOSE 8888
ENV NAME World
ENV PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
CMD ["jupyter", "notebook", "--ip='0.0.0.0'", "--port=8888", "--no-browser", "--allow-root"]
Der Einheitlichkeit wegen wird TensorFlow erst im Notebook installiert.
5.5.3. Erstellen und Trainieren eines Modells
Wie auch schon mit den anderen Frameworks zuvor wird ein Klassifikationsmodell auf dem CIFAR-10 Datensatz trainiert. Dazu wird ein Convolutional Neural Network (CNN) mit TensorFlow implementiert. Die Schritte sind ähnlich wie bei Scikit-learn, jedoch wird hier ein CNN-Modell verwendet, das besser für die Bilderkennung geeignet ist. Allerdings erkennt man schnell, dass durch das Fehlen einer High-Level-API, wie Keras oder die in PyTorch bzw. Scikit-Learn integrierten Funktionen, die Implementierung und das Training eines Modells in TensorFlow deutlich komplexer ist.
1. Laden des Datensatzes:
Der CIFAR-10 Datensatz wird wie zuvor geladen und in Trainings- und Testdaten aufgeteilt.
cifar10_dataset = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10_dataset.load_data()
2. Vorverarbeiten der Daten:
Auch hier werden die Daten normalisiert und standardisiert, um sie für das Training vorzubereiten. Außerdem muss das OneHot-Encoding der Labels hier händisch durchgeführt werden. Außerdem werden von den Trainingsdaten nach der Vorverarbeitung noch Validierungsdaten abgetrennt.
def normalize(images):
images = images.astype("float32") / 255.0
return images
def standardize(images):
mean = np.mean(images, axis=(0, 1, 2, 3))
std = np.std(images, axis=(0, 1, 2, 3))
images = (images - mean) / (std + 1e-7)
return images
def one_hot_encode(labels):
return tf.one_hot(labels.flatten(), depth=10)
train_images = normalize(train_images)
test_images = normalize(test_images)
train_images = standardize(train_images)
test_images = standardize(test_images)
train_labels = one_hot_encode(train_labels)
test_labels = one_hot_encode(test_labels)
# Split training data into training and validation data
validation_size = int(len(train_images) * 0.1) # 10% data for validation
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
3. Definition der Netzwerkarchitektur
Das Modell ist ein Convolutional Neural Network (CNN), das speziell für die Verarbeitung von Bildern entwickelt wurde. Es besteht aus folgenden Schichten:
Conv2D-Schichten: Diese sind die konvolutionellen Schichten, die räumliche Hierarchien von Merkmalen durch die Verwendung von Filtern lernen, die auf die Eingabebilder angewendet werden. Die erste Schicht verwendet 32 Filter der Größe 3x3 und die
reluAktivierungsfunktion. Die folgenden zwei Conv2D-Schichten erhöhen die Anzahl der Filter auf 64, um komplexere Muster zu erkennen.MaxPooling2D-Schichten: Diese Schichten reduzieren die räumliche Größe der Repräsentation, um die Anzahl der Parameter und die Rechenleistung im Netzwerk zu verringern und gleichzeitig relevante Merkmale zu behalten. Sie verwenden ein Pooling-Fenster der Größe 2x2.
Flatten-Schicht: Diese Schicht wandelt die zweidimensionalen Feature-Maps in einen eindimensionalen Vektor um. Dies ist notwendig, um die konvolutionellen Schichten mit den dicht vernetzten Schichten (Dense) zu verbinden.
Dense-Schichten: Die erste Dense-Schicht hat 64 Neuronen und verwendet ebenfalls die
reluAktivierungsfunktion. Die letzte Schicht hat 10 Neuronen, entsprechend den 10 Klassen des CIFAR-10 Datensatzes, und verwendet diesoftmaxAktivierungsfunktion, um eine Wahrscheinlichkeitsverteilung über die verschiedenen Klassen zu erzeugen.
Das Modell wird mit der adam Optimierungsfunktion und dem categorical_crossentropy Verlustfunktion verwendet, was üblich für Multiklassen-Klassifikationsprobleme ist.
Die Architektur ist so gestaltet, dass sie von einfachen zu komplexeren Mustern übergeht und dabei hilft, die verschiedenen Objekte im CIFAR-10 Datensatz effektiv zu klassifizieren. Die Verwendung von MaxPooling hilft dabei, die Dimensionalität zu reduzieren und Overfitting zu vermeiden, während die Dense-Schichten die Entscheidungsfindung des Netzwerks ermöglichen.
Hier zeigt sich der gravierendste Unterschied zu Keras: Die Definition des Modells ist deutlich komplexer und weniger intuitiv als in Keras. Die Schichten müssen manuell definiert und miteinander verbunden werden, was zu einer höheren Komplexität und Fehleranfälligkeit führt.
# Define input images and labels
inputs = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels = tf.placeholder(tf.float32, [None, 10])
# First convolutional layer
conv1 = tf.layers.conv2d(
inputs=inputs,
filters=32,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu)
# First pooling layer
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Second convolutional layer
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu)
# Second pooling layer
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Third convolutional layer
conv3 = tf.layers.conv2d(
inputs=pool2,
filters=64,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu)
# Flatten Layer
flatten = tf.layers.flatten(conv3)
# Dense Layer
dense = tf.layers.dense(inputs=flatten, units=64, activation=tf.nn.relu)
# Logits Layer (without activation)
logits = tf.layers.dense(inputs=dense, units=10)
# Loss- and optimizer function
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels, logits=logits))
optimizer = tf.train.AdamOptimizer().minimize(loss)
# Prediction and accuracy calculation
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
4. Training des Modells
Beim Trainieren mit allein TensorFlow muss das Modell manuell trainiert werden, indem die Daten in Batches aufgeteilt und über mehrere Epochen trainiert werden. Hier wird eine Batch-Größe von 64 und 10 Epochen verwendet. Nach jeder Epoche wird die Genauigkeit auf den Trainings- und Validierungsdaten berechnet und ausgegeben. Die komplette Trainingsfunktion, sowie die Validierung muss händisch implementiert werden.
epochs = 10
batch_size = 64
number_of_batches = len(train_images) // batch_size
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(buffer_size=50000).batch(batch_size)
validation_dataset = tf.data.Dataset.from_tensor_slices((validation_images, validation_labels)).batch(batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(batch_size)
# Initialize all variables
init = tf.global_variables_initializer()
# Create a session and run the training
with tf.Session() as sess:
sess.run(init)
# Trainingsroutine
for epoch in range(epochs):
# Create an iterator for the datasets
train_iterator = train_dataset.make_one_shot_iterator()
next_batch = train_iterator.get_next()
# Iterate over all batches
for _ in range(number_of_batches):
try:
batch_x, batch_y = sess.run(next_batch)
sess.run(optimizer, feed_dict={inputs: batch_x, labels: batch_y})
except tf.errors.OutOfRangeError:
break
# Print training and validation loss and accuracy after each epoch
train_loss, train_accuracy = sess.run([loss, accuracy], feed_dict={inputs: train_images, labels: sess.run(train_labels)})
print('Epoche', epoch, 'abgeschlossen mit Verlust:', train_loss, 'und Genauigkeit:', train_accuracy)
# Validation
validation_loss, validation_accuracy = sess.run([loss, accuracy], feed_dict={inputs: validation_images, labels: sess.run(validation_labels)})
print('Epoche', epoch, 'Validierung abgeschlossen mit Verlust:', validation_loss, 'und Genauigkeit:', validation_accuracy)
5.6. Huggingface 🤗
Hugging Face ist eine führende Plattform für natürliche Sprachverarbeitung (NLP) und maschinelles Lernen, die eine breite Palette an Tools und Bibliotheken anbietet. Ihr bekanntestes Produkt ist die „Transformers“-Bibliothek, die vortrainierte Modelle für verschiedene Aufgaben bereitstellt:
Textklassifikation
Sentimentanalyse
Übersetzung
Textgenerierung
Diese Modelle, basierend auf modernen Architekturen wie BERT, GPT und T5, können einfach angepasst und in verschiedensten Anwendungen integriert werden. Hugging Face bietet zudem eine benutzerfreundliche API und eine umfassende Modell-Hub, in der Nutzer Modelle teilen und herunterladen können.
Darüber hinaus unterstützt die Plattform Entwickler mit detaillierter Dokumentation, Tutorials und einer aktiven Community. Die „Datasets“-Bibliothek ermöglicht einfachen Zugriff auf eine Vielzahl von NLP-Datasets zur Trainings- und Evaluationszwecken. Für Unternehmen bietet Hugging Face skalierbare Lösungen und individuelle Unterstützung an. Ein weiteres wichtiges Feature ist die Integration in beliebte Entwicklungsumgebungen und Cloud-Dienste, was die Implementierung und den Einsatz von NLP-Modellen erleichtert. Insgesamt fördert Hugging Face Innovation und Zusammenarbeit in der NLP-Community.
5.7. Langchain 🦜
LangChain ist ein leistungsfähiges Framework zur Erstellung von Anwendungen, die große Sprachmodelle (LLMs) verwenden. Es bietet eine flexible Infrastruktur zur Verarbeitung, Analyse und Generierung natürlicher Sprache, die sich nahtlos in bestehende Systeme integrieren lässt. Die wichtigsten Funktionalitäten umfassen:
Textgenerierung
Sprachverständnis
Dialogführung
Extraktion von Informationen
LangChain unterstützt verschiedene LLMs und bietet Möglichkeiten zur Feinabstimmung und Anpassung an spezifische Anwendungsfälle. Darüber hinaus umfasst es robuste Funktionen für das Daten- und Pipeline-Management, die es Entwicklern erleichtern, komplexe NLP-Workflows zu erstellen und zu optimieren. Dank seiner skalierbaren Architektur kann LangChain sowohl für kleine Anwendungen als auch für großangelegte Unternehmenslösungen eingesetzt werden. Die benutzerfreundliche API und umfassende Dokumentation ermöglichen eine schnelle Implementierung und Weiterentwicklung von NLP-Projekten.
5.7.1. Unterschiede zwischen HuggingFace und Langchain?
LangChain konzentriert sich im Gegensatz zu HuggingFace eher auf die Erstellung von NLP Anwendungen und deren Infrastruktur. Hinsichtlich der Funktionalität liegt der Schwerpunkt von HuggingFace bei der Modellbereitstellung und -optimierung. Dagegen fokusiert sich LangChain eher auf Werkzeuge für das Erstellen von LLM-Pipelines and dessen Workflow.
5.8. LlamaIndex 🦙
LlamaIndex ist ein leistungsstarkes Framework zur Verwaltung und Optimierung großer Sprachmodelle (LLMs) in Anwendungen. Es bietet effiziente Indexierungs- und Datenstrukturierungsfunktionen, die schnelle und präzise Antworten ermöglichen. Mit adaptiven Algorithmen und fortschrittlichem Datenmanagement verbessert es die Leistung von LLMs und unterstützt verschiedene Datenquellen. Die benutzerfreundliche API und umfassende Dokumentation erleichtern die Integration und Skalierung von NLP-Anwendungen.
Das Framework orientiert sich an den eigenen Daten und versucht eine komplette NLP-Pipeline für das Projekt bereitzustellen. Dabei sind viele Funktionalitäten verfügbar, welche das Laden von Daten aus verschiedenen Datenquellen, wie z.B. Google Drive, Notion oder SQL Datenbank leicht ermöglichen. Mit LLamaIndex kann man speziell auch die Performance von Sprachmodellen evaluieren und überwachen. Ähnlich wie HuggingFace bietet auch Meta mit LLamaHub eine Plattform für die Community. Anders als bei HuggingFace werden dort vorrangig aber nicht Datensätze oder Modelle geteilt, sondern eher Python-Bibliotheken, welche man einfach in sein eigenes NLP-Projekt implementieren kann. Diese Bibliotheken können auch ganz eigene Frameworks, wie beispielsweise Dataloader oder eigene Retrieving-Techniken sein.
5.9. Literaturangaben
Wikipedia-Eintrag PyTorch https://de.wikipedia.org/wiki/PyTorch (abgerufen am 24.05.2024)
PyTorch-Offizielle Webseite https://pytorch.org/get-started/locally/ (abgerufen am 24.05.2024)
Scikit-learn: Machine Learning in Python https://scikit-learn.org/stable/ (abgerufen am 25.05.2024)
Scikit-learn: About us https://scikit-learn.org/stable/about.html (abgerufen am 25.05.2024)
Sciktit-learn: Getting Started https://scikit-learn.org/stable/getting_started.html (abgerufen am 25.05.2024)
Was ist Scikit-Learn? https://databasecamp.de/python/scikit-learn (abgerufen am 25.05.2024)
Wikipedia-Eintrag HuggingFace https://de.wikipedia.org/wiki/Hugging_Face (abgerufen am 28.05.2024)
HuggingFace Tutorials https://huggingface.co/learn (abgerufen am 28.05.2024)
LangChain: About https://www.langchain.com/langchain (abgerufen am 28.05.2024)
LLamaIndex Overview https://www.llamaindex.ai/ (abgerufen am 28.05.2024)
LLamaHub Overview https://llamahub.ai/ (abgerufen am 28.05.2024)
The CIFAR-10 dataset https://www.cs.toronto.edu/~kriz/cifar.html (abgerufen am 30.05.2024)
TensorFlow Introduction https://www.tensorflow.org/learn (abgerufen am 30.05.2024)
TensorFlow 1.x vs 2.x https://www.tensorflow.org/guide/migrate/tf1_vs_tf2 (abgerufen am 30.05.2024)
Keras Installation https://keras.io/getting_started/ (abgerufen am 05.06.2024)
Keras API Dokumentation https://keras.io/guides/ (abgerufen am 05.06.2024)